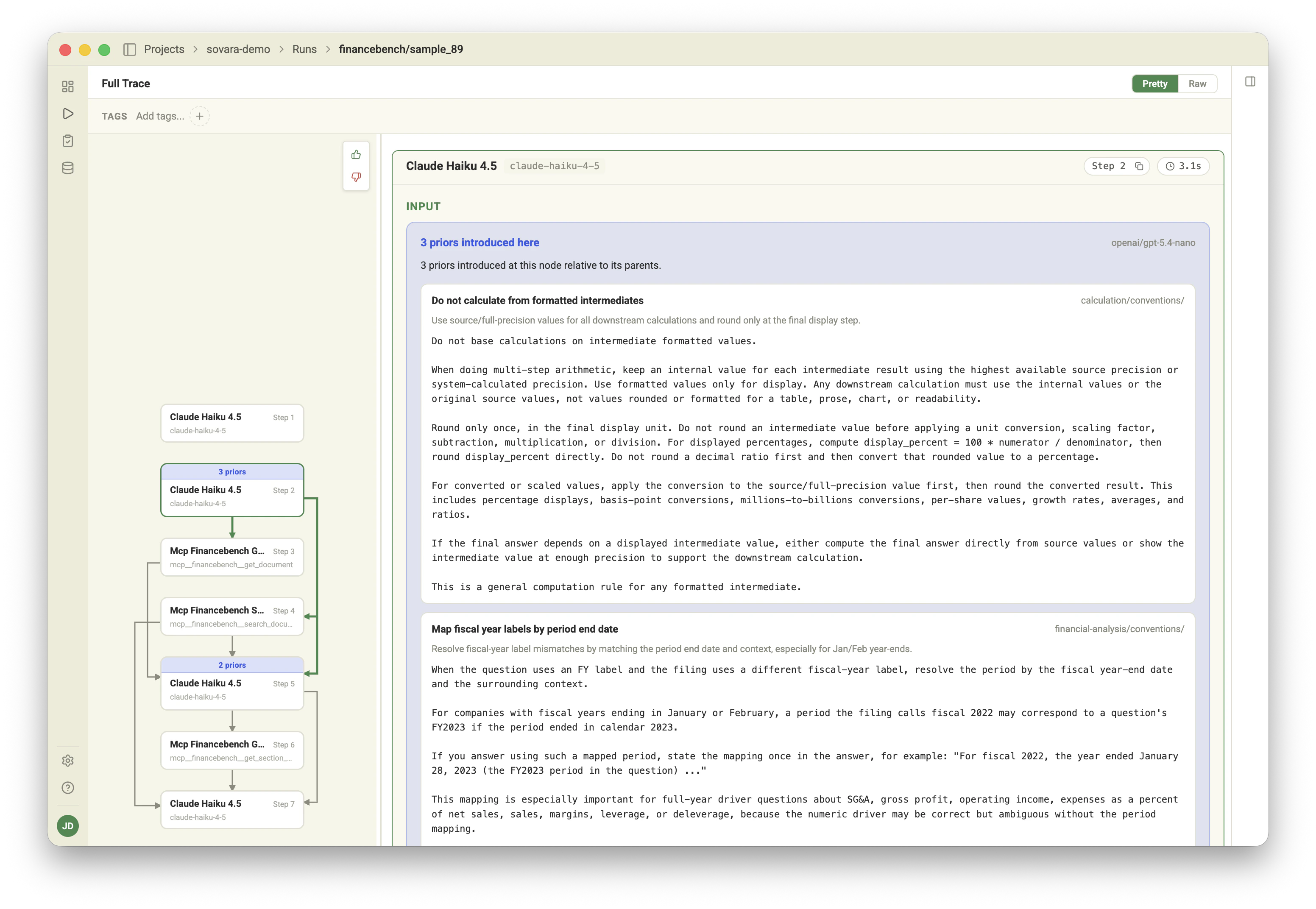
A financial-analysis example
Imagine an agent that answers questions about company liquidity. It can retrieve the current assets, current liabilities, and quick ratio. It can even calculate the ratio correctly. The failure is in the judgment layer. A quick ratio below1.0 usually deserves
caution, but the agent may still call the company liquid because management used
positive language elsewhere in the filing. The lesson is a domain rule:
When assessing liquidity from a quick ratio below 1.0, do not call the
company healthy without checking whether other evidence offsets the short-term
liability risk.
The agent could rediscover that rule by reading many filings, comparing ratios,
and reasoning through the domain from scratch. That is slow. It is also not
reliable enough when the same class of mistake can reappear in production.
Why normal context is not enough
Putting all known guidance at the top of every prompt does not scale. The agent will ignore some of it, the context window gets crowded, and irrelevant rules can distract from the rules that matter now. Leaving the guidance out is also risky. If the agent does not receive the liquidity lesson when the next liquidity question appears, it can repeat the same mistake. This is the gap Lessons handles. Sovara stores durable domain knowledge and makes it available as targeted runtime context.