Why auto-injection is useful
The useful lesson is often not known at the start of a run. A financial-analysis agent might begin with a broad question, retrieve filings, identify a liquidity subtask, and only then need the quick-ratio lesson. Auto-injection lets Sovara consider lessons close to the step where they matter. That keeps the guidance timely and avoids forcing the agent to carry every lesson from the beginning.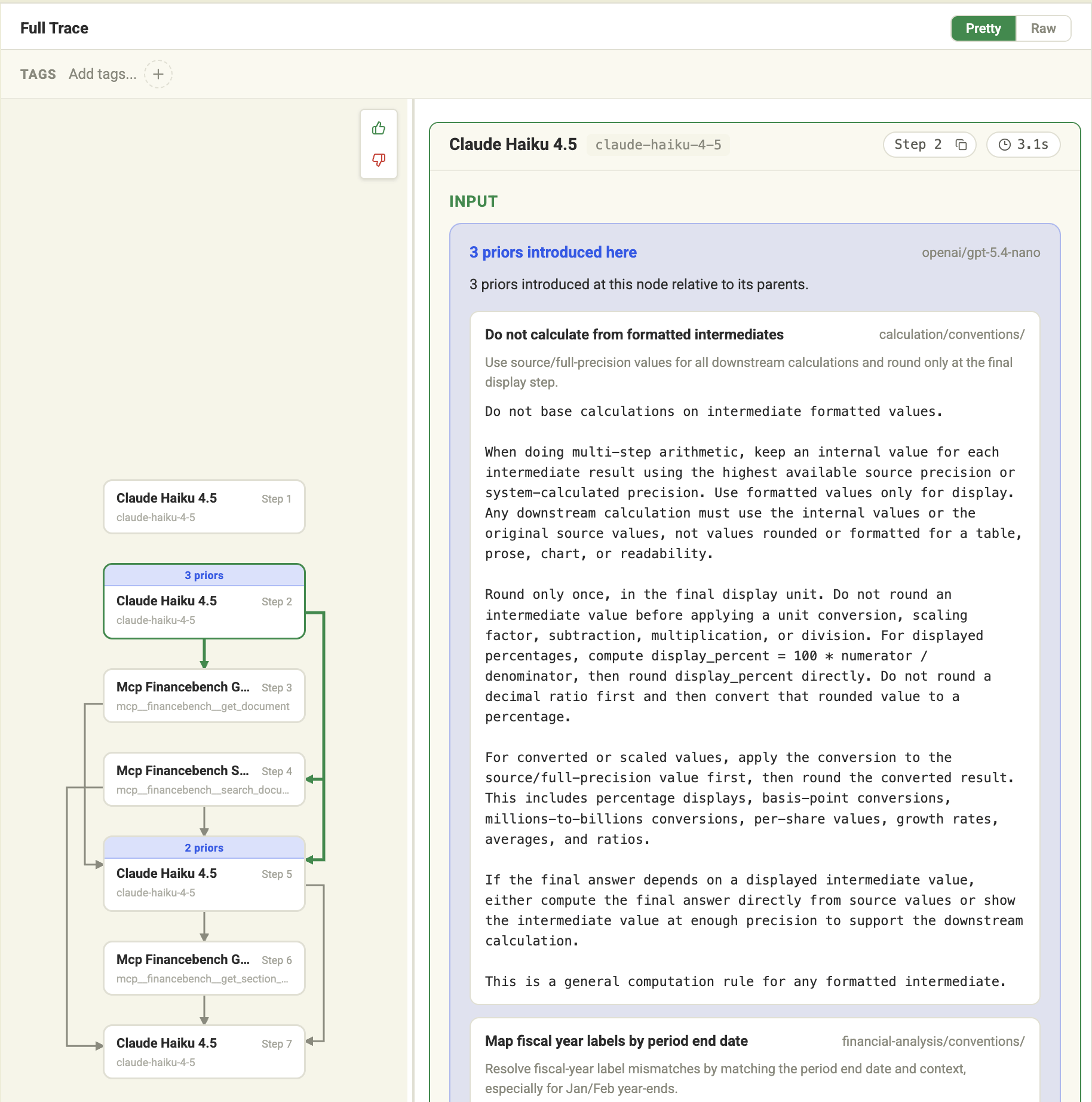
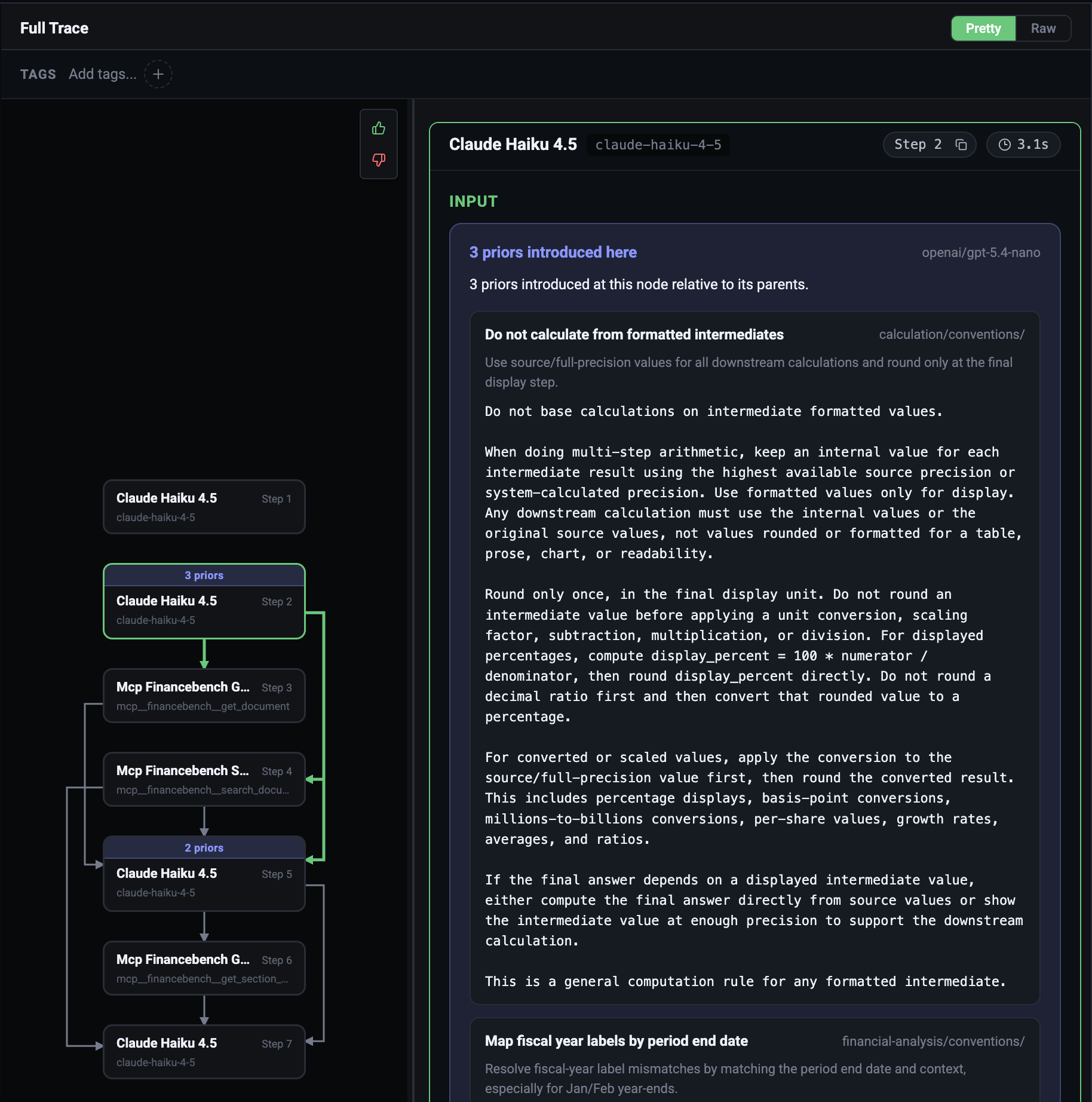
Why not inject everything at the top?
Top-loading all guidance is tempting, but it breaks down quickly:- The relevant context can change during a run
- Early guidance can be stale by the time the agent reaches a later step
- Large prompt blocks dilute attention
- Unrelated lessons can push the agent toward the wrong behavior
Why not always inject?
Even relevant lessons have a cost. Every injected token competes with task context, retrieved evidence, tool output, and the model’s own reasoning budget. Sovara avoids injecting when it should not. It also uses prefix-caching so stable lesson context does not need to be retrieved and inserted repeatedly for the same effective prompt state.Why not let the LLM decide?
An LLM can help reason about context, but it is not the right control point for every injection decision. The model may not know which lesson is needed until after it has already missed the lesson. Sovara keeps more control by evaluating possible injection at the runtime step. That gives the system a chance to apply the right domain lesson before the model answers.Configure injection
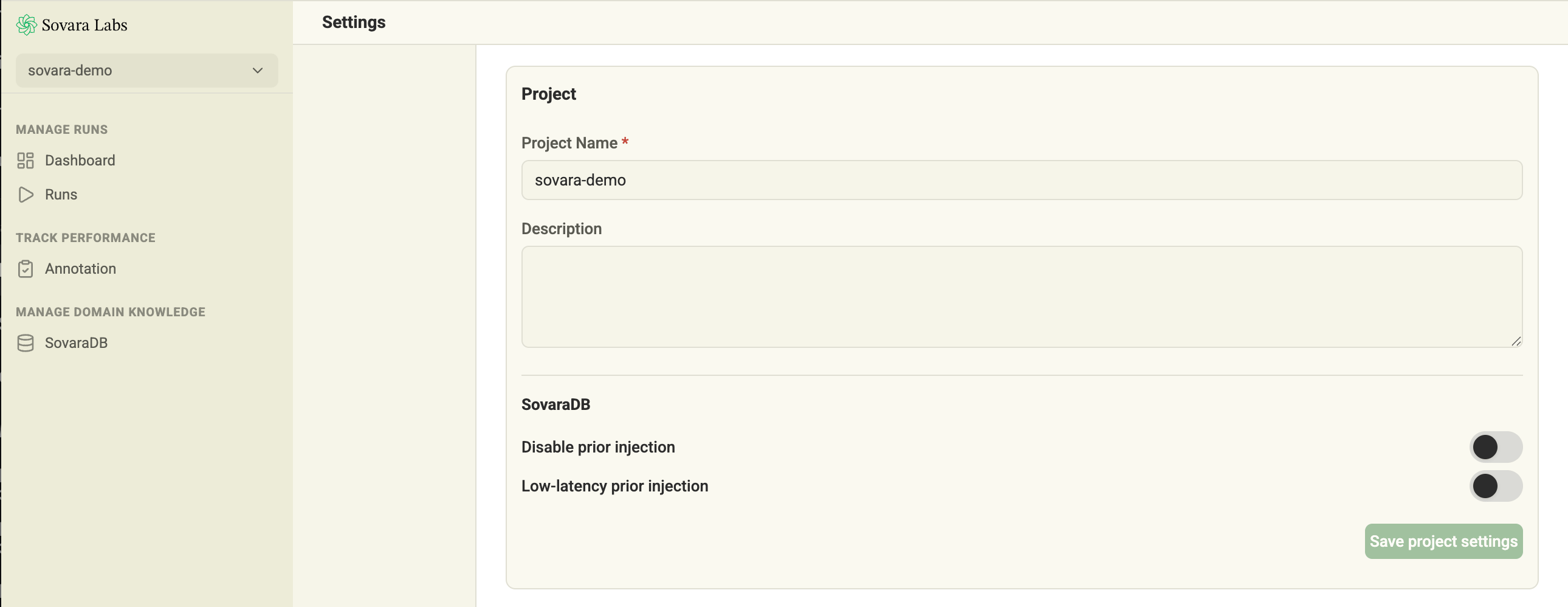
Open Settings and go to the project’s lesson injection settings.- Turn on Disable lesson injection when a project should run without runtime lessons.
- Turn on Low-latency lesson injection for latency-critical applications.
Manual injection
Automatic lesson injection is the normal path. Sovara takes care of retrieving lessons and placing the context under the hood. Use manual injection only when you need explicit control, such as placing the lesson block yourself or retrieving through the active run/subrun lesson scope. Manual injection must happen inside an active Sovara run. When Sovara detects a managed manual lesson block for a call, it skips automatic retrieval for that same call. The manual helper returns only the lesson context string. If it is non-empty, prepend it to the prompt you send to the model; if it is empty, send the prompt without the prefix.- Python
- TypeScript
Skip lesson injection
Usedisable_lesson_injection() around Python code that should be traced but
should not receive automatic lessons.